Разработка алгоритма поиска по базе данных на основе латентно-семантического поиска, ВКР по прикладной информатике

Получите бесплатно демо-версию Демо-версия - дипломная работа, в котрой удалена часть текста, рисунков, таблиц.Посмотреть все услуги дипломной работы на электронную почту.
Введите адрес электронной почты и нажмите "Отправить"
 Автоматизация приема заявок на ремонт и модернизацию персональных компьютеров2 000 ₽
Автоматизация приема заявок на ремонт и модернизацию персональных компьютеров2 000 ₽ Программные комплексы поддержки принятия управленческих решений (учет рабочего времени сотрудников)2 000 ₽
Программные комплексы поддержки принятия управленческих решений (учет рабочего времени сотрудников)2 000 ₽ Разработка методики выбора средств защиты платёжных карт, ВКР защита информации 2 000 ₽
Разработка методики выбора средств защиты платёжных карт, ВКР защита информации 2 000 ₽ Разработка автоматизированной системы учета товаров и продаж для торговой компании2 000 ₽
Разработка автоматизированной системы учета товаров и продаж для торговой компании2 000 ₽Описание
Бакалаврская работа подготовлена и защищена в 2018 году в Московском авиационном институте (национальный исследовательский университет), по направлению подготовки 230100 «Информатика и вычислительная техника», профиль «Системы автоматизированного проектирования».
В нашем мире все увеличивающегося объема данных возникает острая необходимость лучшего хранения и последующей их обработки. Ручная классификация в таких объемах станет очень затратной по времени и человеческому ресурсу. Но эту проблему сможет решить компьютерная автоматическая классификация, в рамках которых автоматизированные комплексы смогут работать с большими объемами данных.
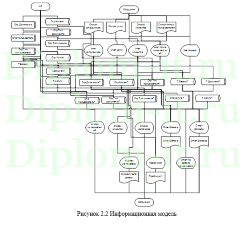
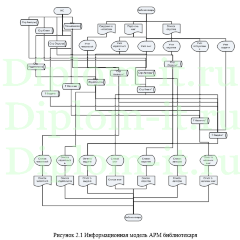
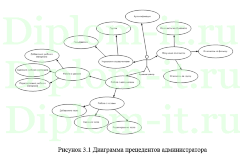
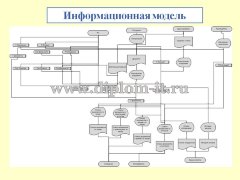
В проекте рассматривается задача создания ИС для автоматического деления всех документов. Система выступает в роли web-портала для разделения документов.
Основным вариантом генерации признакового пространства становится методика ключевых слов. Основными признаками в данной методике становятся лексемы, которые входят в документы, а размерность признаков пространства равняется самому словарю. Но такой метод не может учесть морфологию языка, а также различные связи между словами. Поддержка морфологии реализуется при помощи метода стемминга [2], который основывается на приведении слов к их основной словоформе. Но ведь тогда для каждого языка нужно создать морфологический анализатор, что непременно приведет к возрастающей нагрузке вычислений, а также возникнет задача понимания начального языка документа (если он не будет указан в свойствах), ну и наконец, для отдельных языков создание морфологического анализатора сама по себе проблематичная задача.
В настоящей выпускной квалификационной работе разработана информационная система, позволяющая классифицировать электронные документы с использованием трех методов классификации, а именно метода ближайших соседей, его модифицированного варианта и обобщенного метода ближайших соседей.
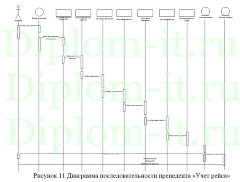
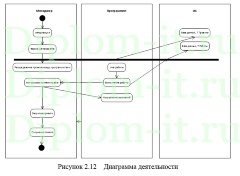
ВКР включает в себя 3 части. Первая описывает методику классификации, алгоритмы и производит постановку задачи для создания ИС автоматического разделения электронных документов, определяются варианты дальнейшей разработки.
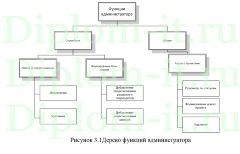
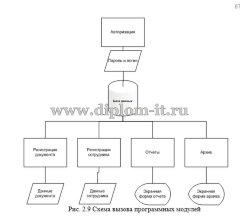
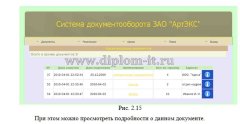
Вторая глава включает описание интерфейса системы, его структуры, созданной БД. Тут же выполняется сравнение применяемых методов: метода ближних соседей, его улучшенного варианта и совокупного метода ближних соседей.
Третья часть включает описание последовательности создания ИС и ее применения.
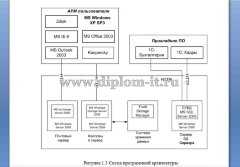
Проект включает в себя программный продукт на базе PHP и СУБД MySQL.
Характеристики
Файлы схем | да |
Год | 2018 |
Программа с исходниками | да, php |

Обратилась к данному производителю услуг в начале мая. Заказала ВКР, курсовую, отчет по практике, речь и презентацию. Почти 100 % оригинальность. Работают быстро. На вопросы отвечают почти моментально. Слегка переделали презентацию и речь по просьбе преподавателя и то, считаю, что какие то замечания должны были быть. ВКР приняли сразу. Изначально отпугнули низкие звезды на отзовике, но я все поняла вовремя и не жалею. Благодарю Вас!) Буду рекомендовать Вас знакомым!)

Обратилась сюда с очень сложной темой. Сделали диплом за месяц, что для меня было спасением. Ребята — профи, взялись за задачу, которая мне не поддавалась.
Есть небольшой нюанс: из-за сжатых сроков не успели отполировать все детали до идеала. Если планируете заказывать, лучше делать это заранее. Но несмотря на это, работа качественная, и я получила «отлично» на защите.
Огромное вам спасибо! Рекомендую ребят всем, кто попал в трудную ситуацию.
Учусь в МГУ на направлении бизнес-информатика. Сначала сомневалась, получится ли совместить требования методички и мои пожелания по структуре. В работе использовались данные из 1С и элементы анализа в Stata. Несколько раз просила внести изменения, всё сделали корректно. В итоге диплом приняли, а оригинальность оказалась выше 88%.
Писала диплом по праву в УрФУ, тема про цифровые права. Сделали с акцентом на судебную практику, уникальность 90%. Сначала сомневалась в надёжности, но общались в чате, скидывали промежуточные главы. На защите отвечала на вопросы легко, потому что материал был логично выстроен. Рекомендую как проверенный сервис.
В РЭУ им. Плеханова готовил диплом по экономике предприятия. Сам текст был нормальный, но особенно полезной оказалась помощь перед защитой. Отдельно заказал ответы на возможные вопросы комиссии. На самой защите несколько вопросов совпали почти дословно.