Разработка нейросетевого классификатора электронной почты, ВКР по прикладной информатике в экономике
Получите бесплатно демо-версию Демо-версия - дипломная работа, в котрой удалена часть текста, рисунков, таблиц.Посмотреть все услуги дипломной работы на электронную почту.
Введите адрес электронной почты и нажмите "Отправить"
 Разработка автоматизированной системы учета товаров и продаж для торговой компании2 000 ₽
Разработка автоматизированной системы учета товаров и продаж для торговой компании2 000 ₽ Применение DLP-систем как инструмента обеспечения информационной безопасности компании, диплом по защите информации2 000 ₽
Применение DLP-систем как инструмента обеспечения информационной безопасности компании, диплом по защите информации2 000 ₽ Информационная система обслуживания заявок сотрудников строительной компании, диплом по информатике в экономике2 000 ₽
Информационная система обслуживания заявок сотрудников строительной компании, диплом по информатике в экономике2 000 ₽ Построение защищенного электронного документооборота в организации, диплом по защите информации2 000 ₽
Построение защищенного электронного документооборота в организации, диплом по защите информации2 000 ₽Описание
Работа написана и представлена в 2018 году.
В нашем мире растущий объём информации в электронном виде так или иначе нуждается в классификации для оптимального хранения и обработки. Ручной анализ при таком объеме текстов станет мега затратным как по финансам, так и по человеко-часам. Данную проблему может решить компьютерная авто классификация, в рамках которой компьютерные комплексы справляются с большими объемами данных.
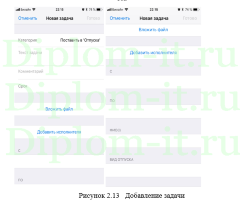
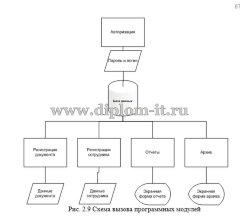
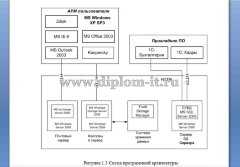
В проекте решается задача разработки ИС для автоматического разделения электронных документов. Система является неким веб-порталом для разделения документов.
Сама ВКР имеет 3 части. В первой описаны методы и алгоритмы классификации и выполнена постановка задачи на создание ИС для автоматического разделения электронных документов, а также выбраны средства разработки.
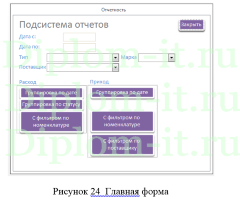
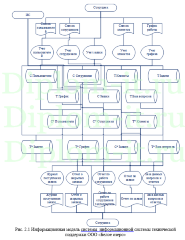
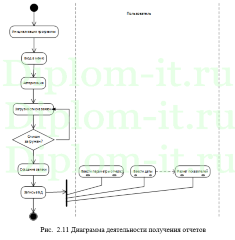
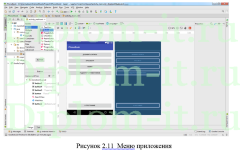
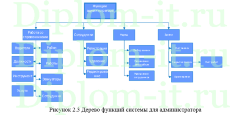
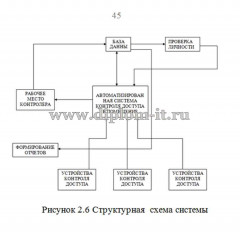
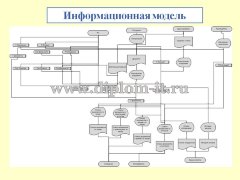
Вторая глава описывает интерфейс системы, ее структуру, в том числе созданную БД. Тут также проводится проверка новой системы и сравнение применяемых методик, а именно метода ближних соседей, его улучшенного варианта и совокупного метода ближних соседей.
Третья глава включает ЖЦ классификатора и рассчитывает цену разработки.
Разделение текстов — сортировка документов по некоторым категориям — одна их подобных задач.
Методы разделения текстовых документов основаны на стыке пары областей — машинного обучения и поиска данных. Совокупная часть этих областей —методы представления документов и оценка уровня разделения текстов, а различия только в вариантах конкретного поиска.
Главными областями использования классификации текстов становятся: фильтрация спама; разделение новостей; авторская проверка.
Объекты классификации — гипертекстовые и текстовые документы и их части — слабо структурированы различными данными. Многие алгоритмов разделения работают с формальным описанием объектов в рамках векторной модели конкретного документа [1]. В этой модели сам документ выражен вектором, а конкретная длина п, где п — сумма признаков, а г-я компонента вектора отражает вес г-го признака. Для внедрения модели представления важно изначально определить признаковое пространство, а также найти алгоритм подсчета весов. Число выбранной модели представления при конкретном алгоритме разделения и определенным эталонном тестовом наборе документов оценивают по некоторым параметрам:
Уровень разделения: базовый критерий (зависит также от алгоритма разделения);
Размер признакового пространства: при единой последовательности лучшее признаковое пространство меньшей размерности;
Размер итоговой модели разделения: при неизменной точности лучше компактные модели;
Длительность обучения и классификации: особый критерий, который зависит от описанных выше;
Понимание морфологии языка: данный показатель связан в описанными выше, в частности, понимание морфологии приводит к наиболее точным и компактным моделям разделения.
Самым явным вариантов создания признакового пространства становится методика ключевых слов [1, 2]. Признаками в данном методе станут лексемы, входящие в документы, а размерность пространства признаков будет равной размерности словаря. Но такой метод, к примеру, включает морфологию языка, а также некоторые связи между словами. Поддержку морфологии обычно реализуют при помощи стемминга [2], базирующегося на приведении слов к их исходной словоформе. Но в этом случае для любого языка требуется морфологический анализатор, что приводит к повышенной вычислительной нагрузке, а также рождает задачу нахождения языка документа в случае его отсутствия, и важно понимать, что для части языков создание морфологического анализатора очень непростая задача.
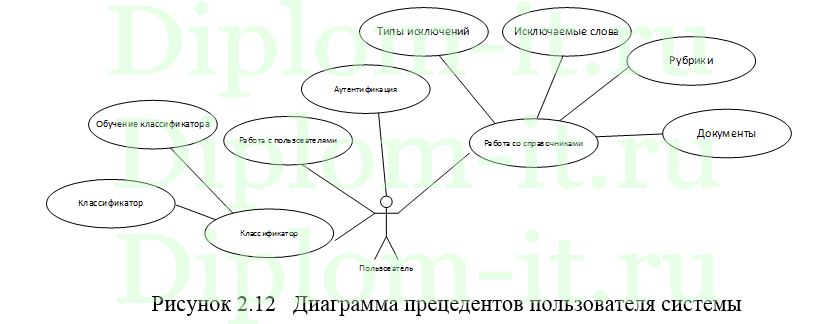
В данной ВКР создана ИС, которая помогает классифицировать электронные документы с применением 3 методов классификации; методики ближнего соседа, его обновленного варианта и совокупного метода ближайших соседей.
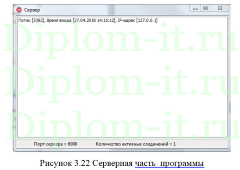
Сам проекта помимо пояснительной записки содержит программу на PHP и СУБД MySQL.
Характеристики
Файлы схем | да |
Год | 2018 |
Программа с исходниками | да, php |

Спасибо, работа пришла мгновенно. Буду рекомендовать друзьям.

Обратилась к данному производителю услуг в начале мая. Заказала ВКР, курсовую, отчет по практике, речь и презентацию. Почти 100 % оригинальность. Работают быстро. На вопросы отвечают почти моментально. Слегка переделали презентацию и речь по просьбе преподавателя и то, считаю, что какие то замечания должны были быть. ВКР приняли сразу. Изначально отпугнули низкие звезды на отзовике, но я все поняла вовремя и не жалею. Благодарю Вас!) Буду рекомендовать Вас знакомым!)
Обратилась сюда с очень сложной темой. Сделали диплом за месяц, что для меня было спасением. Ребята — профи, взялись за задачу, которая мне не поддавалась.
Есть небольшой нюанс: из-за сжатых сроков не успели отполировать все детали до идеала. Если планируете заказывать, лучше делать это заранее. Но несмотря на это, работа качественная, и я получила «отлично» на защите.
Огромное вам спасибо! Рекомендую ребят всем, кто попал в трудную ситуацию.
Учусь в МГУ на направлении бизнес-информатика. Сначала сомневалась, получится ли совместить требования методички и мои пожелания по структуре. В работе использовались данные из 1С и элементы анализа в Stata. Несколько раз просила внести изменения, всё сделали корректно. В итоге диплом приняли, а оригинальность оказалась выше 88%.
Писала диплом по праву в УрФУ, тема про цифровые права. Сделали с акцентом на судебную практику, уникальность 90%. Сначала сомневалась в надёжности, но общались в чате, скидывали промежуточные главы. На защите отвечала на вопросы легко, потому что материал был логично выстроен. Рекомендую как проверенный сервис.